Aakash BhardwajIndustry use case of OpenShiftOpenShift offers automated installation, upgrades, and lifecycle management throughout the container stack (the operating system…3 min read·Jan 12, 2022----
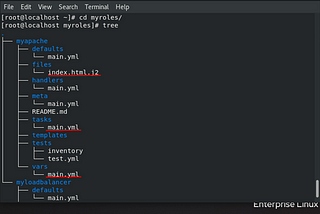
Aakash BhardwajAnsible roles for load balancer and apache webserverWhat are Ansible Roles?3 min read·Jul 10, 2021----
Aakash BhardwajMongoDBWhat is MongoDB? MongoDB is a document-oriented, no sequel(NOSQL) database. It replaces the concept of roles of conventional relational…6 min read·Jul 10, 2021----
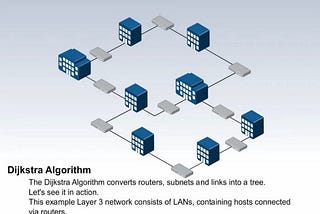
Aakash BhardwajHow Open Short Path First Routing Protocol is implemented using Dijkstra Algorithm behind the sceneWorking of Dijkstra on OSPF Protocol:2 min read·Jul 10, 2021----
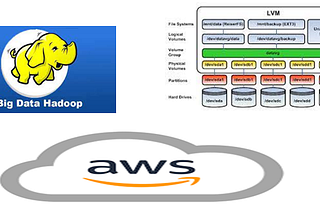
Aakash BhardwajIntegrating LVM with Hadoop🔅Integrate LVM with Hadoop and provide Elasticity to DataNode Storage 🔅Increase or Decrease the Size of Static Partition in Linux…4 min read·Jul 10, 2021----
Aakash BhardwajSocketCreate your own Chat Servers, and establish a network to transfer data using Socket Programing by creating both Server and Client machine…1 min read·Jul 9, 2021----
Aakash BhardwajNokia: Enabling 5G and DevOps at a Telecom Company with KubernetesArchitecture9 min read·Jul 9, 2021----
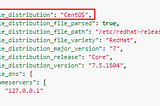
Aakash BhardwajAnsible factsAnsible facts are data related to your remote systems, including operating systems, IP addresses, attached filesystems, and more. You can…2 min read·Jul 8, 2021----